年度
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96

- 1.
Statistical inference
- (A)
refers to the process of drawing inferences about the sample based on the
characteristics of the population- (B)
is the same as descriptive statistics
- (C)
is the process of drawing inferences about the population based on the information
taken from the sample- (D)
is the same as a census.
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 2.
Given P(A) = 0.40 , P(B) = 0.60 , P(A∩ B) = 0.24 . Which of the following is true?
- (A)
A and B are independent
- (B)
A and B are not mutually exclusive
- (C)
A and B are collectively exhaustive
- (D)
None of the above.
- 題型:多選題
- 難易度:尚未記錄
- 登入看解答
- 3.
Which of the following are characteristics of the normal probability distribution?
- (A)
The mean, median, and mode are equal
- (B)
The mean of the distribution can be negative, zero, or positive
- (C)
The distribution is symmetrical
- (D)
The standard deviation must be 1.
- 題型:多選題
- 難易度:尚未記錄
- 登入看解答
- 4.
Which of the following statements are correct regarding the t-distribution?
- (A)
t distribution approaches the standard normal curves as sample sizes become
large.- (B)
t test is quite robust.
- (C)
t test is also referred to as the Student’s test.
- (D)
All of above are correct
- 題型:多選題
- 難易度:尚未記錄
- 登入看解答
- 5.
Which of the following statements about properties of point estimators are correct?
- (A)
If the expected value of the sample statistic is equal to the population parameter
being estimated, the sample statistic is said to be an unbiased estimator of the
population parameter- (B)
The point estimator with the larger standard error is said to have less relative
efficiency than the other- (C)
A point estimator is said to be consistent if the values of the point estimator tend to
become closer to the population parameter as the sample size becomes larger- (D)
All of above are correct
- 題型:多選題
- 難易度:尚未記錄
- 登入看解答
- 6.
Which of the following statements for Poisson distribution are correct?
- (A)
The mean and variance of Poisson distribution are equal
- (B)
The expected number of occurrences is not necessary to hold constant throughout
the experiment- (C)
As a rule of thumb, if n > 20 and np ≤ 7 , the approximation is close enough to
use the Poisson distribution for binominal problems- (D)
Each occurrence is independent of the other occurrences
- 題型:多選題
- 難易度:尚未記錄
- 登入看解答
- 7.
Which of the following statements for Exponential distribution are not correct?
- (A)
it is a family of distribution
- (B)
it is a continuous distribution.
- (C)
it describes random occurrences over some interval
- (D)
it is skewed to the left.
- 題型:多選題
- 難易度:尚未記錄
- 登入看解答
- 8.
The key difference between the binomial and hypergeometric distribution is that with
the hypergeometric distribution- (A)
the probability of success must be less than 0.5
- (B)
the trials are independent of each other
- (C)
the probability of success changes from trial to trial
- (D)
the population is finite and known
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 9.
Chebyshev’s Theorem is important because
- (A)
it explains an unusual mathematical phenomenon
- (B)
it enables us to give meaning to a sample standard deviation
- (C)
it gives the fraction of the measurements in a sample that fall within k standard
deviation’s of the sample mean- (D)
it explains why the sample mean is a good measure of central tendency
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 11.
Stratified sampling is generally more efficient than simple random sampling if:
- (A)
only a few strata are used in the stratification
- (B)
each strata contains about the same variability as the entire population with respect
to the characteristic of interest- (C)
non-sampling errors are of no consequence or expected to be slight
- (D)
the item within each strata are relatively homogeneous.
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 12.
台灣高鐵公司宣稱其台北至高雄列車的平均誤點不超過八分鐘,消基會懷疑高鐵
公司宣稱的真實性,因此決定調查其平均誤點時間,以作為統計檢定之用,請問
以下陳述何者正確。- (A)
型二誤差為列車誤點時間不超過八分鐘,但消基會認為列車誤點時間超過八分
鐘。- (B)
若雙方均同意以十二分鐘作為檢驗標準點,則增加調查班次數對雙方均有利。
- (C)
若檢定出來之P 值很大,則對高鐵公司較有利。
- (D)
以上皆非。
- 題型:多選題
- 難易度:尚未記錄
- 登入看解答
- 13.
下列陳述何者正確
- (A)
母體變異數未知,但已知母體為常態分配時,若用Z 分配與t 分配對母體平均
數計算信賴區間,則兩者信賴區間長度一樣。- (B)
母體為常態分配,且母體變異數為已知時,若信賴水準不變,則母體平均數的
信賴區間長度會隨樣本數的增加而變小。- (C)
信賴區間的長度會隨信賴水準的增加而變大。
- (D)
以上皆非。
- 題型:多選題
- 難易度:尚未記錄
- 登入看解答
- 14.
Which of the following statements for nonparametric statistics are not correct?
- (A)
Nonparametric testes are usually not as widely available and well known as
parametric tests.- (B)
Nonparametric statistics are based in more assumptions about the population than
parametric statistics.- (C)
For small sample, the calculations for many nonparametric statistics can be tedious.
- (D)
Probability statements obtained from most nonparametric tests are exact
probabilities.
- 題型:多選題
- 難易度:尚未記錄
- 登入看解答
- 15.
When the smallest and the largest percentage of items are removed from a data set and
the mean is computed, the mean of the remaining data is:- (A)
the median
- (B)
the mode
- (C)
greater than the mean of the original data
- (D)
less than the mean of the original data
- (E)
none of the above are correct
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 16.
A consumer test group wants to determine the difference in gasoline mileage of two
new developed hybrid car A and B . researchers took 50 cars for the car A and
also 50 cars for the car B , and tested each car on one tank of gas. The sample average
for the car A was 21.45 kilometer per litter (KM/L), with a standard deviation of 3.46
KM/L. The sample average for the car B was 24.6 KM/L, with a standard deviation
of 2.99 KM/L. Assume all samples are normal distribution. Construct a 95% confidence
interval to estimate the difference in the mean gas mileage between the car A and car
B . (4%)
- 題型:問答題
- 難易度:尚未記錄
- 17.
The manager of a book store wants to determine what proportion of people who enter
the store use credit cards for their purchases. What size sample should he take so that at
98% confidence the error will not be more than 4%? (4%)
- 題型:問答題
- 難易度:尚未記錄
- 18.

- 題型:問答題
- 難易度:尚未記錄
- 19.
A book dealer received a lot of 1,500 books from a printer. The dealer plans to sample
12 books and use single-sample acceptance sampling to reach a decision about the lot.
If more than one book is defective, the dealer will reject the lot. Suppose the printer is
fairly certain that only 3% of the books are defective. What is the producer’s risk?
Suppose 12% of the lot of books is defective and that this rate would be too high for the
dealer to accept. what is the dealer’s risk in using this acceptance sampling? (4%)
- 題型:問答題
- 難易度:尚未記錄
- 20.
A telephone survey conducted by a Research Company found that 43% of Taiwanese
expect to save more money next year than they saved last year because of the financial
crisis. 45% of those surveyed plan to reduce debt next year. Of those who expect to save
more money next year, 81% plan to reduce debt next year. A Taiwanese is selected
randomly. What is the probability that this person neither expect to save more money
next year nor plans to reduce debt next year? (4%)
- 題型:問答題
- 難易度:尚未記錄
- 21.
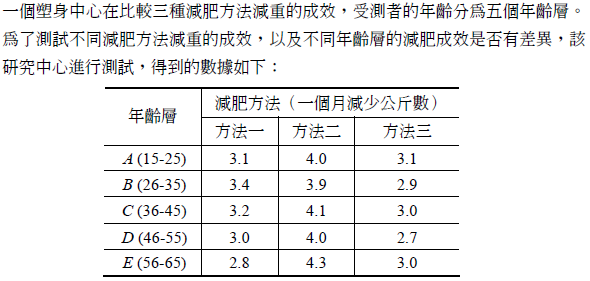
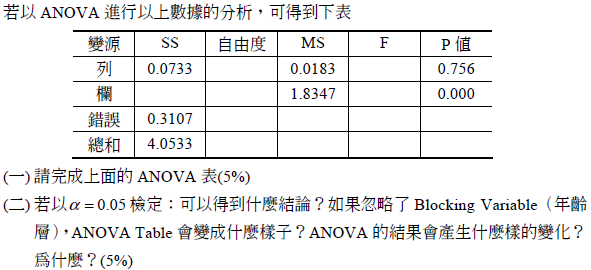
- 題型:問答題
- 難易度:尚未記錄
- 22.

- 題型:問答題
- 難易度:尚未記錄