年度
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96

- 1.
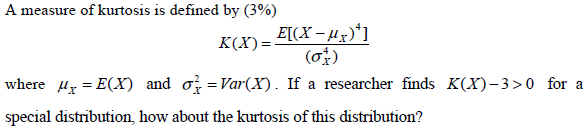
- (A)
Platykurtic.
- (B)
Leptokurtic.
- (C)
Normal distribution
- (D)
This distribution has different kurtosis with normal distribution, but we cannot
judge by neasure of kurtosis directly
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
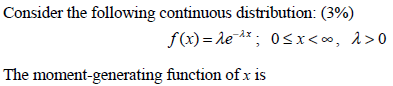
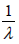
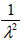
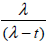
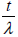
- 3.
On a 12-question multiple-choice test, there are four possible answers for each
question, of which one is correct. Suppose that a student guesses on each question. Let
X equal the number of correct answers. What is E(X ) ? (3%)- (A)
3
- (B)
6
- (C)
9
- (D)
10
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 4.
Bowl B1 contains two red and five white chips, and bowl B2 contains four red and
three chips. A fir die is cast. If the output is a multiple of 3 (namely, 3 or 6), a chip is
taken from bowl B2 ; Otherwise a chip is taken from bowl B1 . Given that the selected
chip is red, what is the conditional probability that it was taken from bowl B1 . (3%)- (A)
8/21
- (B)
1/3
- (C)
1/2
- (D)
10/21
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 5.
If X is normally distributed with a mean of 6 and a variance of 25. What is
P(| X − 6 | < 5) ? (3%)- (A)
0.65
- (B)
0.9544
- (C)
0.5403
- (D)
0.6826
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 6.
Let X have a Poisson distribution with a mean of 4. What is P(2 ≤ X ≤ 5) ? (3%)
- (A)
0.532
- (B)
0.693
- (C)
0.65
- (D)
0.477
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答

- 8.
If Z is a random variable that is t distribution with T −1 degree of freedom, which
distribution W = Z 2 converge to? (3%)- (A)
χ 2 (T −1)
- (B)
t(T −1)
- (C)
N(0, T −1)
- (D)
F(1, T −1)
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 9.
If it is known that X has a mean of 33 and a variance of 16, then, which is the upper
bound for P(| X − 33 | ≥ 14) ? (3%)- (A)
0.71
- (B)
0.89
- (C)
.084
- (D)
0.92
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
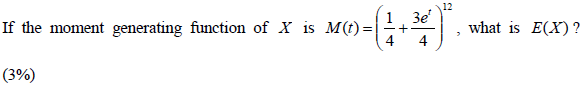
- 11.
The conditional distribution of Y given X = x , Pr(Y = y | X = x) , is (3%)
- (A)
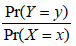
- (B)
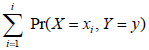
- (C)
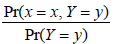
- (D)
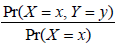
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 12.
Estimation of the IV regression model (3%)
- (A)
requires exact identification
- (B)
allows only one endogenous regressor, which is typically correlated with the error
term.- (C)
requires exact identification or overidentification
- (D)
is only possible if the number of instruments is the same as the number of
regressors
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 13.
The distinction between endogenous and exogenous variables is (3%)
- (A)
that exogenous variables are determined inside the model and endogenous variables
are determined outside the model- (B)
dependent on the sample size: for n > 100 , endogenous variables become
exogenous- (C)
depends on the distribution of the variables: when they are normally distributed,
they are exogenous, otherwise they are endogenous- (D)
whether or not the variables are correlated with the error term
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 14.
The AR( p) model (3%)
- (A)
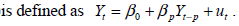
- (B)
represents Yt as a linear function of p of its lagged values.
- (C)
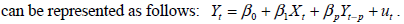
- (D)
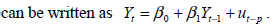
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 15.
The confidence interval for the sample regression function slope (3%)
- (A)
can be used to conduct a test about a hypothesized population regression function
slope- (B)
can be used to compare the value of the slope relative to that of the intercept
- (C)
adds and subtracts 1.96 from the slope
- (D)
allows you to make statements about the economic importance of your estimate.
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 16.
Under the least squares assumptions (zero conditional mean for the error term, Xi
and Yi being i.i.d., and Xi and ui having finite fourth moments), the OLS
estimator for the slope and intercept (3%)- (A)
has an exact normal distribution for n > 15 .
- (B)
is BLUE
- (C)
has a normal distribution even in small samples
- (D)
is unbiased
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 17.
Imagine you regressed earnings of individuals on a constant, a binary variable (“Male”)
which takes on the value 1 for males and is 0 otherwise, and another binary variable
(“Female”) which takes on the value 1 for females and is 0 otherwise. Because females
typically earn less than males, you would expect (3%)- (A)
the coefficient for Male to have a positive sign, and for Female a negative sign
- (B)
both coefficients to be the same distance from the constant, one above and the other
below.- (C)
none of the OLS estimators to exist because there is perfect multicollinearity
- (D)
this to yield a difference in means statistic
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 18.
When you have an omitted variable problem, the assumption that E(ui | Xi ) = 0 is
violated. This implies that (3%)- (A)
the sum of the residuals is no longer zero
- (B)
there is another estimator called weighted least squares, which is BLUE
- (C)
the sum of the residuals times any of the explanatory variables is no longer zero
- (D)
the OLS estimator is no longer consistent
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答

- 20.
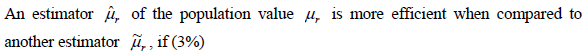
- (A)
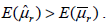
- (B)
it has a smaller variance.
- (C)
its c.d.f. is flatter than that of the other estimator.
- (D)
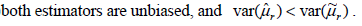
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 21.
(一) Why we employ the normality assumption in classical linear regression model?
What is the Central Limit Theorem? (10%)
(二) What is the type I error? What is the type II error? Can we minimize both the errors
simultaneously? (10%)
- 題型:問答題
- 難易度:尚未記錄
- 22.

- 題型:計算題
- 難易度:尚未記錄