年度
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 100
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 99
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 98
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 97
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96
- 96


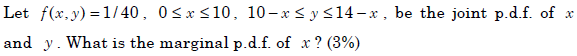
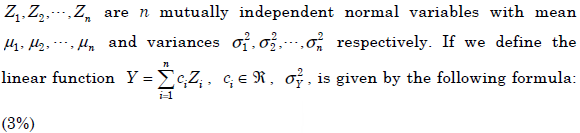
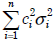
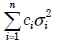
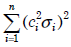
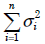
- 4.
If we test a statistical hypothesis, we have the following condition:
Rejecting null hypothesis and accepting alternative hypothesis when null
hypothesis is true. The condition is called (3%)- (A)
P-value.
- (B)
Significance level of test.
- (C)
Type II error.
- (D)
Type I error.
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答

- 6.
If it is known that X has a mean of 25 and a variance of 16, then, which
is the upper bound for P(|X − 25|≥ 12) ? (3%)- (A)
1/5
- (B)
1/4
- (C)
1/9
- (D)
1/16
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
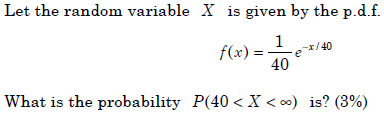
- 8.
If we collect n observation points, we want to estimate a simple
regression function E(Y ) = β1 X1 from observed data. What is the normal
equation about this regression? (3%)- (A)
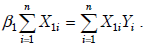
- (B)
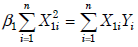
- (C)
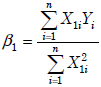
- (D)
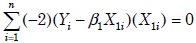
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 9.
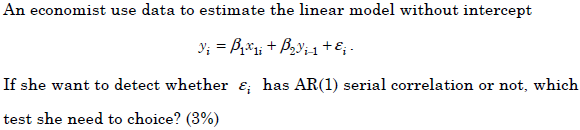
- (A)
Breusch-Pagan test.
- (B)
Goldfeld-Quandt test.
- (C)
Durbin-Waston test.
- (D)
Durbin h test.
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 10.

- (A)
skew to the left.
- (B)
skew to the right.
- (C)
symmetric.
- (D)
this distribution id skew, but we cannot judge by measure of skewness
directly.
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 11.
The confidence interval for the sample regression function slope (3%)
- (A)
can be used to compare the value of the slope relative to that of the
intercept.- (B)
adds and subtracts 1.96 from the slope.
- (C)
can be used to conduct a test about a hypothesized population
regression function slope.- (D)
allows you to make statements about the economic importance of your
estimate.
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 12.
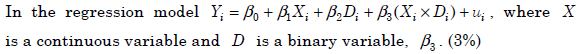
- (A)
has a standard error that is not normally distributed even in large
samples since D is not a normally distributed variable.- (B)
indicates the difference in the slopes of the two regressions.
- (C)
has no meaning since (Xi ×Di) = 0 when Di =0
- (D)
indicates the slope of the regression when Di = 1 .
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 13.
Sample selection bias (3%)
- (A)
occurs when a selection process influences the availability of data and
that process is related to the dependent variables.- (B)
is more important for nonlinear least squares estimation than for OLS.
- (C)
results in the OLS estimator being biased, although it is still consistent.
- (D)
is only important for finite sample results.
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 14.
For the polynomial regression model. (3%)
- (A)
the critical values from the normal distribution have to be changed to
1.962, 1.963, etc- (B)
you can still use OLS estimation techniques, but the t-statistics do not
have an asymptotic normal distribution- (C)
you need new estimation techniques since the OLS assumptions do not
apply any longer- (D)
the techniques for estimation and inference developed for multiple
regression can be applied
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 15.
The power of the test (3%)
- (A)
is the probability that the test actually incorrectly rejects the null
hypothesis when the null is true.- (B)
is one minus the size of the test.
- (C)
is the probability that the test correctly rejects the null when the
alternative is true.- (D)
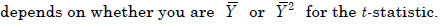
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 16.
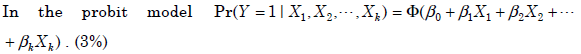
- (A)
the slopes tell you the effect of a unit increase in X on the probability of
Y.- (B)
the β ′ s do not have a simple interpretation
- (C)
β0 is the probability of observing Y when all X’s are 0.
- (D)
β0 cannot be negative since probabilities have to lie between 0 and 1.
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 17.
If the errors are heteroskedastic, then (3%)
- (A)
the usual formula cannot be used for the OLS estimator
- (B)
your model becomes overidentified
- (C)
the OLS estimator is not BLUE
- (D)
the OLS estimator is still BLUE as long as the regressors are
nonrandom
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 18.
Consider a competitive market where the demand and the supply depend
on the current price of the good. Then fitting a line through the
quantity-price outcomes will (3%)- (A)
estimate neither a demand curve nor a supply curve
- (B)
give you the exogenous part of the demand in the first stage of TSLS
- (C)
give you an estimate of the demand curve
- (D)
enable you to calculate the price elasticity of supply
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答
- 19.
If you had a two regressor regression model, then omitting one variable
which is relevant (3%)- (A)
can result in a negative value for the coefficient of the included variable,
even though the coefficient will have a significant positive effect on Y if
the omitted variable were included.- (B)
makes the sum of the product between the included variable and the
residuals different from 0.- (C)
will always bias the coefficient of the included variable upwards.
- (D)
will have no effect on the coefficient of the included variable if the
correlation between the excluded and the included variable is negative.
- 題型:單選題
- 難易度:尚未記錄
- 登入看解答

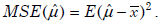
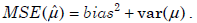
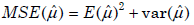
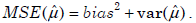
- 21.
Let the p.d.f. of X be defined by f (x) = x3 / 4 , 0 < x < 2 . Find the p.d.f. of
Y = X2 . (10%)
- 題型:計算題
- 難易度:尚未記錄
- 22.
Suppose the random variable X has the moment-generating function
M(t) = (1 − t)−2 , t < 1, find E(X) and σ2 . (10%)
- 題型:計算題
- 難易度:尚未記錄
- 23.

- 題型:計算題
- 難易度:尚未記錄
- 24.
The logarithm of the likelihood function (L) for estimating the population
mean and variance for an i.i.d. normal sample is as follows:
- 題型:計算題
- 難易度:尚未記錄